
운영체제
- Firmware : OS와 유사하지만 SW를 추가로 설치할 수 없음
3.1 운영체제와 컴퓨터
운영체제의 역할
- CPU 스케줄링과 프로세스 관리
- 메모리 관리
- 디스크 파일 관리
- I/O 디바이스 관리
운영체제의 구조

- 시스템콜 : 커널 영역의 기능을 프로세스가 사용할 수 있도록 user mode에서 kernel mode로 전환해주는 interface
- Process control :
fork(),exit(),wait() - File manipulation :
open(),read(),write(),close() - Device manipulation :
ioctl()(InputOutputControl),read(),write() - Information maintenance :
getpid(),alarm(),sleep() - Communication :
pipe(),shmget()(ShareMemoryget),mmap()(Memorymap) - Protection :
chmod(),umask(),chown()
- Process control :
- PC : CPU register 중의 하나, 다음 fetch 될 명령어의 주소를 가리킴
- Interrupt : 보통 하드웨어 인터럽트를 말함
- Trap : SW에서 거는 인터럽트의 종류
- 발생할 경우 system call을 호출하거나 예외처리를 하게 됨
- modebit :
0(kernel mode),1(user mode)1일 경우 Previleged instruction을 실행하지 못함
3.1.2 컴퓨터의 요소
- CPU : CU, ALU, Register로 구성됨
- ALU(Arithmetic and Logical Unit) : 산술, 논리 연산 담당
- 가산, 누산, 보수, shift, 오버플로우, 데이터(연산에 사용할 데이터 기억)
- CU(Control Unit) : 명령어 해독, 제어신호 전송 등의 제어 담당
- Register
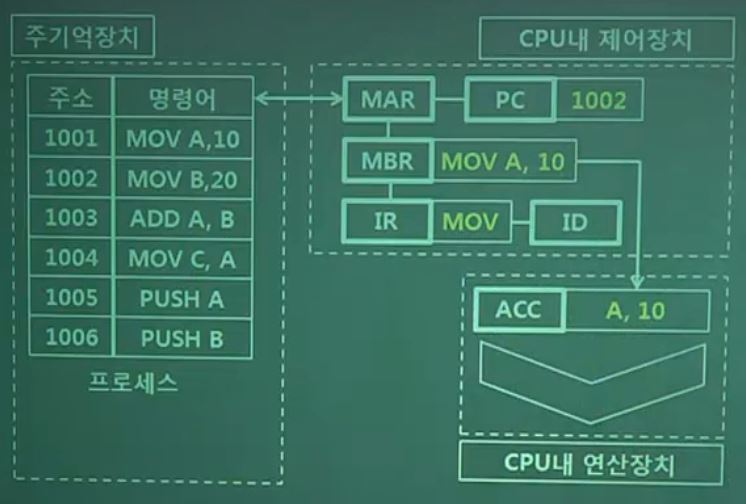
- PC(Program Counter) : 다음 수행할 instruction의 주소 저장
- MAR(Memory Address Register) : 현재 접근할 주소를 기억
- MBR(Memory Buffer Register) : RAM의 명령이나 데이터를 임시로 기억
- IR(Instruction Register) : Instruction을 기억
- ID(Instruction Decoder) : IR에서 호출된 명령을 해독하고 수행
- ALU(Arithmetic and Logical Unit) : 산술, 논리 연산 담당
- Device controller : IO device들의 제어 유닛
- DMA(Direct Memory Accesss) : 장치 제어기가 CPU의 도움 없이 DMA controller를 이용해 데이터를 직접 메모리로 전송하는 입출력 방식
- CPU는 상태 정보, 제어 정보만 전송
- 타이머 : CPU에 시간 정보를 제공
- 클럭을 세어 스케줄링에 활용
3.2 메모리
3.2.1 메모리 계층
- Register : CPU 안에 있는 메모리
- Cache : L1, L2, L3 캐시
- 주기억장치 : RAM
- 보조기억장치 : HDD, SSD
캐시
- 캐시 : 데이터를 미리 복사해놓는 임시 저장소
- 장치 간의 속도 차에 의한 병목 현상을 줄이기 위함
- 캐싱 계층 : 속도 차이를 해결하기 위한 계층(e.g. 주기억장치 : 캐시 메모리와 보조기억장치 사이의 캐싱 계층)
- 지역성의 원리 : 캐시를 설정할 때 지역성을 통해 판단해야 함
- Temporal locality : 최근 사용한 데이터에 다시 접근하는 특성
- Spatial locality : 최근 접근한 데이터가 저장된 메모리나 그 근처를 접근하는 특성(e.g. 배열)
캐시히트와 캐시미스
- 캐시히트 : 캐시에서 원하는 데이터를 찾은 경우
- CPU 내부 버스를 사용하기 때문에 빠름
- 캐시미스 : 캐시에 데이터가 없어 주메모리로 가서 데이터를 찾아오는 것
- 시스템 버스를 사용하기 때문에 느림
- 캐시매핑
- Register, RAM 간의 캐싱 계층인 cache를 예로 설명
- Register는 [1, 10], RAM은 [1, 100]의 인덱스를 가진다고 가정
- 직접(Directed) 매핑 : 1 : [1, 10], 2 : [2, 20]와 같이 매핑
- 처리가 빠르지만 충돌이 잦음
- 연관(Associative) 매핑 : 순서를 일치시키지 않고 관련 있는 캐시와 매핑
- 모든 블록을 탐색해야 하기 때문에 속도가 느리지만 충돌이 적음
- 집합 연관(Set associative) 매핑 : 순서는 일치시키지만 그룹화해서 매핑(직접+연관)
- [1, 5] : [1, 50]과 같이 매핑
- Register, RAM 간의 캐싱 계층인 cache를 예로 설명
- 웹 브라우저에서의 캐시 : 사용자 정보, 인증 모듈 등을 브라우저에 저장해서 사용자 정보 표시, 중복 요청 방지 등으로 사용
- 쿠키 : 만료 기한이 있는 4KB 크기의 key-value 저장소
- httponly 옵션 설정해서 document.cookie로 볼 수 없도록 해야 함
- 보통 서버에서 만료 기한을 정함
- 로컬 스토리지 : 만료 기한이 없는 10MB 크기의 key-value 저장소
- 브라우저를 닫아도 유지됨
- 도메인 단위로 저장, 생성됨
- HTML5를 지원하는 브라우저에서 동작
- client에서만 수정 가능
- 세션 스토리지 : 만료 기한의 없는 5MB 크기의 key-value 저장소
- 탭 단위로 생성하고 탭을 닫을 때 삭제됨
- HTML5를 지원하는 브라우저에서 동작
- client에서만 수정 가능
- 쿠키 : 만료 기한이 있는 4KB 크기의 key-value 저장소
- DB의 캐싱 계층
- redis DB 계층을 캐싱 계층으로 둬서 성능을 향상시키기도 함
- redis에서 캐시 미스가 날 경우 메인 DB에 쿼리 보냄
- redis DB 계층을 캐싱 계층으로 둬서 성능을 향상시키기도 함
3.2.2 메모리 관리
가상 메모리
- 오버레이 기법
- 프로그램 자체에서 일부만 메모리에 올려서 차지하는 메모리 자체를 줄이는 기술
- 시스템이 충분한 메모리를 갖지 않는 경우에는 동일하게 메모리 부족 오류가 발생함
-
가상 메모리 기법
- 코드 영역은 메모리에 있어야 하지만 나머지 부분은 메모리에 올라가지 않아도 프로세스를 실행가능함
- 나머지 부분은 보조 기억장치에 위치함
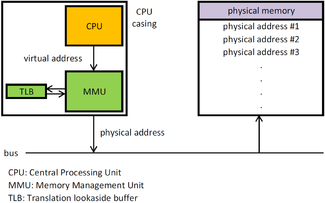
- logical address : 가상 메모리 주소
- physical address : 실제 메모리상의 주소
- MMU(Memory Management Unit) : logical → physical로 주소를 변환해줌
- TLB(Translation Lookaside Buffer) : 메모리와 CPU 사이의 주소 변환을 위한 캐시
- TLB에 변환 정보가 없을 경우 CPU가 Page Table까지 가게 됨
- Page fault : logical address는 존재하지만 page table을 거친 physical address에는 저장된 데이터가 없을 경우 발생함
- Page : 가상 메모리를 사용하는 최소 크기 단위
- Frame : 실제 메모리를 사용하는 최소 크기 단위
- 데이터의 지역성 때문에 자주 일어나진 않음
- Swapping : page fault의 해결 방법
- 프로세스는 page table에 사용하려는 page가 있는지 확인
- 없다면 page fault exception을 발생시키고 커널 모드로 전환
- OS는 page table을 통해 보조 기억장치에서의 해당 page의 위치를 확인
- 해당 page를 physical memory에 로드함
- page table 갱신
- 유저 모드로 다시 전환 후 원래 작업 실행
Thrashing
- Page fault의 비율이 증가하여 CPU 이용률이 떨어지는 현상
- 해결 방법
- 컴퓨터 자원 수직 확장 : 메모리 증설, SDD로 교체
- Working set : 지역성을 통해 자주 참조된 페이지들의 집합인 워킹셋을 만들어 워킹셋이 메모리에 동시에 올라가게 함
- 워킹셋 전체 프레임의 크기가 할당된 페이지의 프레임보다 크면 thrashing이 발생함
- page fault가 없어도 워킹셋을 관리해야 함
- PFF(Page Fault Frequency) : page fault rate가 적으면 프로세스에 할당된 page frame의 수를 감소시키고, 많으면 frame을 더 할당함
메모리 할당
- 시작 메모리 위치, 메모리 할당 크기를 통해 할당함
연속 할당
- 고정 분할(fixed partition allocation) : 물리적 메모리를 영구적인 분할로 나눠두고 각 분할에 하나의 프로세스를 적재해 실행함
- 분할의 크기는 서로 다르게 할 수도 있음
- 메모리에 올릴 수 있는 프로그램의 수, 최대 크기가 제한됨
- 외부 단편화, 내부 단편화 발생 가능
- 가변 분할(variable partition allocation) : 메모리에 적재되는 프로그램에 따라 분할의 크기, 개수가 동적으로 변함
- 프로그램 크기에 맞춰 분할하기 때문에 내부 단편화는 발생하지 않음
- 프로그램들을 적재했다가 몇 개가 종료되고 불연속적으로 메모리 가용 공간(홀)이 생기는데, 이후의 프로그램보다 크기가 작을 경우 외부 단편화 발생
- 해결 방법
- first-fit : 최초로 탐색한, 적재 가능한 홀에 올림(시간복잡도가 작음)
- best-fit : 적재 가능한 홀들 중 가장 작은 크기의 홀에 올림(공간복잡도가 작음)
- worst-fit : 적재 가능한 홀들 중 가장 큰 크기의 홀에 올림
- Memory compaction : 디스크 조각모음처럼 메모리에 올라간 프로세스들을 모음
불연속 할당
- Paging : 메모리를 페이지와 동일한 크기(보통 4KB)로 나눠 프로그램을 분할해서 각각의 프레임에 할당함
- TLB(Translation Lookaside Buffer)에 page table을 저장하고 참조함
- 프로그램을 분할하기 때문에 외부 단편화가 발생하지 않음
- 마지막 페이지에서는 내부 단편화가 발생할 수 있음(프레임이 4KB인데 저장할 조각은 2KB)
- Segmentation : 프로세스를 세그먼트 단위로 나눠서 할당
- Segment : 코드, 데이터, 스택, 힙 등의 메모리 구조 또는 함수와 같이 프로세스를 나누는 논리적 단위
- segment table을 사용함
- segment 크기 만큼의 공간을 할당하기 때문에 내부 단편화가 발생하지 않음
- segment 크기가 클 경우 외부 단편화 발생 가능
- Paged segmentation : segment, page 순서로 프로세스를 분할해서 메모리에 할당함
- 주소 변환을 두 번해야 함
페이지 교체 알고리즘
- Belady’s Anomaly : 프레임 수에 따른 page fault의 발생 횟수의 수열이 단조 감소가 아닌 현상
- 프레임을 늘렸을 때 page fault가 증가하는 경우가 있을 수 있음
- Optimal(Offline) 알고리즘 : 가장 오래 사용되지 않을 페이지를 교체하는 알고리즘
- page-fault가 가장 적음
- 구현 불가능, 성능 비교의 기준으로 사용됨
- FIFO 알고리즘 : 먼저 할당된 페이지를 먼저 교체함
- Belady’s Anomaly 발생 가능
- LRU(Least Recently Used) 알고리즘 : 가장 오래 사용되지 않은 페이지를 교체함
- hash table, dll(호출 기록 스택 역할)로 구현
- 별도의 저장소가 필요하기 때문에 오버헤드 발생
- LFU(Least Frequently Used) 알고리즘 : 가장 참조 횟수가 낮은 페이지를 교체함
- 가장 최근에 불러온 페이지가 교체될 수 있고 구현이 더 복잡함
- MFU(Most Frequently Used) 알고리즘 : 가장 참조 횟수가 높은 페이지를 교체함
- 가장 많이 사용된 페이지가 앞으로 사용되지 않을 것이라는 가정 하에 동작함
- NUR(Not Used Recently, clock) 알고리즘 :
- 페이지별로 참조 비트, 변형 비트가 존재하고, 교체 대상을 선정할 때 참조 비트를 우선적으로 봄
- 동일 그룹(00, 01, 10, 11) 내에서는 무작위 선택 → 적은 오버헤드
3.3 프로세스와 스레드
- 프로세스 : 메모리에 올라와 실행되고 있는 프로그램의 인스턴스
- CPU 스케줄링의 대상이 되는 작업
- 스레드 : 프로세스 내에서 실행되는 흐름의 단위
3.3.1 프로세스와 컴파일 과정
- Pre-processing
*.h,*.c→*.i(전처리된 소스 파일)- 주석 제거, 헤더 파일 삽입, 매크로 치환
- Compilation
*.i→*.s(어셈블리어 파일)- 언어의 문법 검사, static한 영역(Data, BSS)의 메모리 할당
- Assembly
*.s→*.o(오브젝트 파일)- Object code : 사람이 알아볼 수 없는 기계어
- Linking
*.o,*.a,*so→ executable- Linking : 함수를 사용하는 오브젝트 파일과 함수를 구현한 오브젝트 파일(라이브러리 등)을 연결시키는 작업
- 정적 라이브러리 : 빌드시 필요한 모든 코드를 실행 파일에 넣음
- 동적 라이브러리 : DLL 형태로 필요할 때만 참조
3.3.2 프로세스의 상태
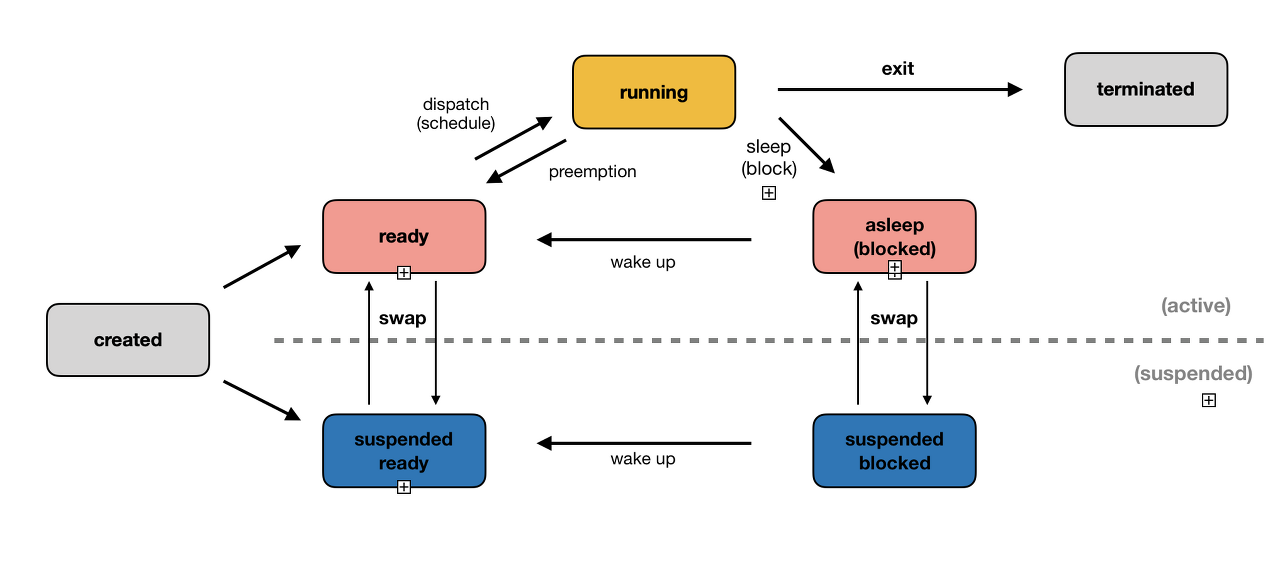
- created :
fork(),exec()등의 함수를 통해 프로세스가 생성된 상태- PCB가 할당됨
fork(): 부모 프로세스의 주소 공간을 그대로 복사, 새로운 자식 프로세스 생성- 부모의 비동기 작업은 상속하지 않음
exec(): 새로운 프로세스 생성
- ready : 모든 자원을 할당 받은 상태에서 CPU 소유권 대기
- suspended ready : 메모리를 제외한 다른 자원들을 보유한 상태
- running : CPU 소유권과 메모리를 받아 instruction을 수행 중인 상태
- blocked : 어떤 이벤트가 발생한 후 프로세스가 중단된 상태
- I/O 디바이스 interrupt, I/O 작업 중인 상태
- suspended blocked : blocked에서 메모리를 잃은 상태
- terminated : 프로세스 실행이 완료되어 CPU, 메모리를 반환한 상태
- 부모가 자식을 강제 종료시키는 abort, kill 등의 명령으로 종료할 때도 발생함
3.3.3 프로세스의 메모리 구조
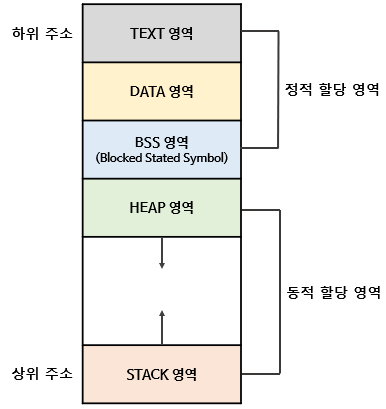
- stack : 지역 변수, 파라미터, 함수가 저장됨
- 컴파일할 때 크기가 결정됨
- stack overflow : stack이 heap 영역을 침범했을 때 발생
- heap : 동적 할당할 때 사용됨
- BSS : 초기화되지 않은 전역/static 변수가 0으로 초기화되어 저장됨
- data : 0이 아닌 값으로 할당된 전역/static 변수가 저장됨
- text : 프로그램 명령이 기계어로 저장됨
3.3.4 PCB
- Process Control Block : 프로세스의 상태 정보를 저장하는 구조체
- 프로세스가 생성될 때 만들어짐
PCB의 구조
| PID | pid |
|---|---|
| Process state | 프로세스의 상태 |
| Program counter | 다음 instruction의 주소를 저장 |
| Register | Accumulator, CPU register 등의 정보 |
| CPU scheduling information | CPU 스케줄러에 의해 중단된 시간, CPU 점유 시간 등의 정보 |
| Memory information | 프로세스 주소공간 정보 |
| Process information | 페이지 테이블, 스케줄링 큐 포인터, 소유자 등 |
| Device I/O Status | 프로세스에 할당된 I/O 장치 목록 |
| Pointer | 부모/자식 프로세스, 자원에 대한 포인터 |
| Open file list | 프로세스에 의해 열린 파일 목록 |
Context switching
- PCB를 교환하는 과정
- 프로세스에 할당된 시간이 끝나거나 인터럽트에 의해 발생함
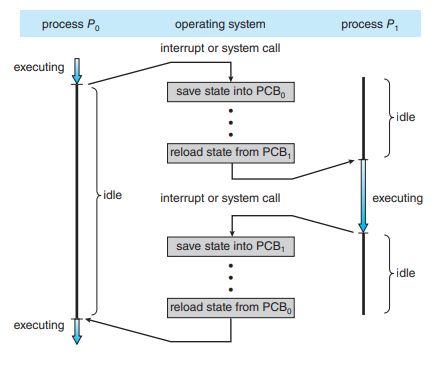
- context switching이 일어날 때 idle time이 발생함
- context switching이 일어날 때 발생하는 부하
- cache flushing, reloading 과정이 필요함
- 캐시, 메모리 등의 다양한 테이블 수정
- 스레드는 스택 영역을 제외한 모든 메모리를 공유하기 때문에 스레드에서의 context switching은 비용이 적게 들어감
3.3.5 멀티프로세싱
- 하나 이상의 일을 병렬로 처리할 수 있음
- 특정 프로세스에 문제가 발생하더라도 다른 프로세스를 이용해 처리 가능하기 때문에 신뢰성이 높음
- 웹 브라우저 : 브라우저, 렌더러, 프럴그인, GPU 등의 프로세스 존재
- IPC(Inter Process Communication) : 프로세스끼리 데이터를 공유 및 관리하는 방법
- 공유 메모리, 파일, 소켓, 익명 파이프, 명명 파이프, 메시지 큐 등이 존재함
- 메모리가 완전히 공유되는 스레드보단 속도가 떨어짐
- 공유 메모리 : 여러 프로세스가 하나의 메모리를 공유하는 것
- 파일이나 소켓(TCP, UDP)를 통해서도 프로세스간 통신 가능
- 익명 파이프 : FIFO 방식으로 읽히는 파이프를 사용
- 단방향의 읽기/쓰기 전용 파이프를 만들어 작동함
- 부모, 자식 프로세스 간에만 사용 가능
- 명명 파이프 : 단방향/이중 파이프를 사용한 서버와 하나 이상의 클라이언트의 통신
- 여러 파이프를 동시에 사용 가능
- 프로세스 또는 다른 네트워크와도 통신 가능
- 메시지 큐 : 메시지를 큐 형태로 관리하는 것
- 커널의 전역 변수 등으로 관리됨
- 다른 방식들에 비해 직관적이고 간단하게 구현
3.3.6 스레드와 멀티스레딩
- 스레드 : 프로세스의 실행 가능한 가장 작은 단위
- 한 프로세스는 여러 스레드를 가질 수 있음
- 멀티스레딩 : 프로세스 내 작업을 여러 개의 스레드로 처리하는 기법
- 스레드끼리 자원을 공유하기 때문에 효율성이 높음
- 하나의 스레드에 문제가 생기면 전체 프로세스가 영향을 받음
- 동기화 문제(병목현상, 데드락 등) 발생 가능
- 한 스레드가 block 되어도 다른 스레드가 running일 수 있기 때문에 중단되지 않고 빠른 처리 가능
- 스레드끼리 자원을 공유하기 때문에 효율성이 높음
3.3.7 공유 자원과 임계 영역
공유 자원
- 각 프로세스, 스레드가 함께 접근할 수 있는 자원이나 변수
- race condition : 두 개 이상의 프로세스가 공유 자원을 동시에 사용해 그 순서에 의해 결괏값이 달라질 수 있는 상태
임계 영역
- 공유 자원에 접근하는 코드 부분
- Entry section : 임계 구역에 진입을 요청하는 코드
- Exit section : 임계 구역을 빠져나옴을 알리는 코드
- 해결을 위한 조건
- Mutual exclusion : 한 프로세스가 임계 구역에서 실행 중이라면 다른 프로세스들은 임계 구역에서 실행될 수 없음
- Progress(No deadlock) : 임계 구역에서 실행 중인 프로세스가 없을 때 몇 개의 프로세스가 임계 구역에 진입하려 하면 진입 순서는 이들에 의해서만 결정되어야 하고, 이 선택은 무한정 연기되면 안됨
- Bounded waiting(No starvation) : 한 프로세스가 임계 구역에 진입 신청한 후부터 요청이 허용될 때까지 다른 프로세스가 임계 구역에 진입할 수 있는 횟수가 제한되어야 함
- 뮤텍스, 세마포어, 모니터로 해결 가능
- 모두 lock 매커니즘(쓸 때 잠구고 사용 후 잠금 해제) 기반
- Mutex
- 잠금, 잠금 해제 두 가지의 상태만 가짐
- Semaphore
- counter를 이용해 자원에 동시에 접근할 수 있는 프로세스를 제한함
S(counter),wait()(자신의 차례가 올 때까지 기다리는 함수),signal()(다음 프로세스로 순서를 넘겨주는 함수)- Binary semaphore : counter가 0이나 1만 가짐
- Mutex는 잠금을 기반으로 상호배제가 일어나고 binary semaphore는 신호를 기반으로 상호 배제가 일어남
- Mutex는 동시에 하나의 스레드만 접속 가능, binary semaphore는 동시에 여러 스레드가 접속 가능
- Mutex는 잠금한 스레드만 해제 가능, binary semaphore는 다른 스레드가 signal() 호출 가능
- Counting semaphore : counter의 범위가 0 이상
- 모니터
- 배타 동기 queue : 공유 자원을 점유 중인 스레드가 lock을 가지고 대기하는 공간
- 조건 동기 queue : 공유 자원의 lock이 해제되기를 기다리는 스레드들이 대기하는 공간
- 새 스레드는 조건 동기로 블록된 스레드를 깨울 수 있음
- 깨워진 스레드는 현재 스레드가 나가면 재진입 가능
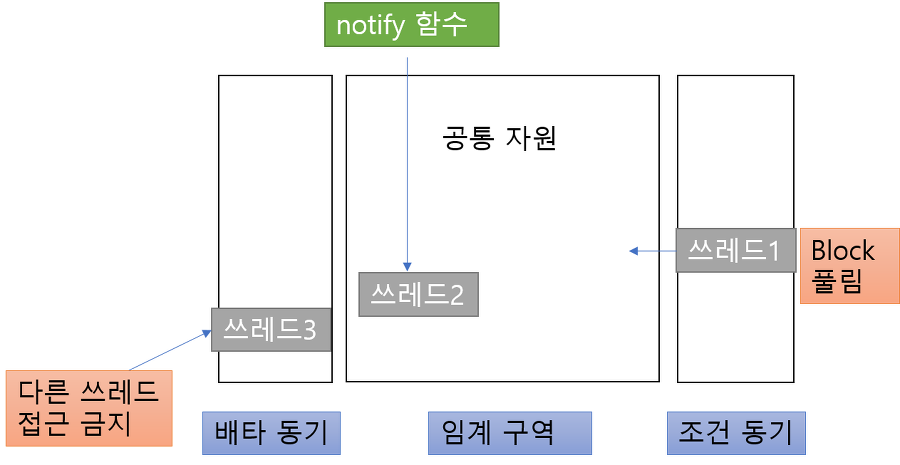
- 스레드 1의 synchronized 함수 실행
- 스레드 1의 wait() 실행, 스레드 2의 synchronized 실행
- 스레드 2의 noitfy() 실행
- Java에서의 모니터
synchronized: 함수에 키워드를 적용시키면 상호배타 조건을 만족하는 함수로 만들어줌wait(): 진입한 스레드를 조건 동기 queue에 block시킴notify(): block된 스레드 하나를 깨움notifyAll(): block된 모든 스레드를 깨움- 특정 작업이 완료된 후 수행해야 할 작업이 여러 개가 있을 수 있음
- mutex, semaphore는 어셈블리어 수준에서 구현, 모니터는 고급 언어 수준에서 구현
- 뮤텍스, 모니터는 binary semaphore와 동일하게 공유 자원을 접근할 수 있는 키가 하나 뿐임
- 모니터는 키의 획득, 해제를 처리해주는 부분이 캡슐화되어 있지만, semaphore는 키 해제, 공유 자원 접근을 직접 처리해야 함
3.3.8 교착 상태
- 둘 이상의 프로세스들이 자원을 점유한 상태에서 서로 다른 프로세스가 점유하고 있는 자원을 요구하며 기다리는 현상
- 교착 상태 발생의 필요 충분 조건
- 상호 배제(Mutual Exclusion) : 한 번에 한 개의 프로세스만 공유 자원 사용
- 점유와 대기(Hold and Wait) : 최소 하나의 자원을 점유하고 있으면서 다른 프로세스가 사용중인 자원을 추가로 점유하기 위해 대기하는 프로세스가 존재
- 비선점(non-preemption) : 이미 할당된 자원은 사용이 끝날 때까지 강제로 빼앗을 수 없음
- 환형 대기(Circular Wait) : 공유 자원, 프로세스의 구조가 원형이면서 앞이나 뒤 프로세스의 자원을 요구해야 함
- 해결 방법
- Prevention : 교착 상태 발생 조건 중 하나를 제거
- 자원 낭비가 가장 심함
- Avoidance : 교착 상태가 발생하면 은행원 알고리즘 등을 사용해 피해감
- 은행원 알고리즘 : 교착 상태 가능성이 없을 때만 자원이 할당됨
- Detection : 교착 상태가 발생했는지 점검
- Recovery : 교착 상태를 일으킨 프로세스를 종료하거나 자원을 선점
- Prevention : 교착 상태 발생 조건 중 하나를 제거
3.4 CPU 스케줄링 알고리즘
- CPU 스케줄러는 알고리즘에 따라 프로세스에서 해야 할 일을 스레드 단위로 CPU에 할당함
- CPU 스케줄링이 발생하는 경우
- 프로세스가 실행 → 대기 상태로 전환
- I/O 요청, 자식 프로세스 종료를 기다리기 위해 wait() 호출 등
- 프로세스가 실행 → 준비 완료 상태로 전환
- 인터럽트 발생
- 프로세스가 대기 → 준비 완료 상태로 전환
- I/O 종료
- 프로세스가 종료될 때
- 1, 4번은 반드시 다른 프로세스로의 전환이 일어나야 하지만 2, 3번은 현재 프로세스가 계속 실행될 수 있음
- 비선점(Nonpreemptive) 스케줄링 : 1, 4만 스케줄링이 일어남
- 선점 스케줄링 : 1, 2, 3, 4 모두 스케줄링이 일어남
- 비선점 스케줄링은 비효율을 초래할 수 있음
- 1, 4번은 반드시 다른 프로세스로의 전환이 일어나야 하지만 2, 3번은 현재 프로세스가 계속 실행될 수 있음
- 프로세스가 실행 → 대기 상태로 전환
- 스케줄링 고려사항
- 처리량 : 단위 시간당 완료된 프로세스 수
- 총 처리 시간 : 준비 큐 대기시간 + CPU 실행 시간 + I/O 시간
- 대기 시간 : 준비 큐에서 대기하는 시간의 합
- 응답 시간 : 유저가 하나의 요구를 제출한 뒤 첫 번째 응답이 나오는데 걸리는 시간
3.4.1 비선점형 스케줄링
- FCFS(First Come, First Served) : FIFO와 같음
- 준비 큐에서 오래 기다리는 Convoy effect가 발생할 수 있음
- SJF(Shortest Job First) : 실행 시간이 가장 짧은 것 먼저 할당
- 실행 시간이 긴 프로세스가 실행되지 않는 starvation이 발생할 수 있음
- 평균 대기 시간이 가장 짧은 최적의 알고리즘
- 실제로는 실행 시간을 알 수 없기 때문에 이전의 실행 시간을 보고 판단
- 새 프로세스가 준비 큐에 도착했을 때 현재 실행 중인 프로세스의 남은 시간보다 새 프로세스의 CPU burst가 더 짧을 수 있음
- 이때 프로세스 전환이 일어나면 선점형, 실행 중인 프로세스가 끝날 때까지 실행되면 비선점형으로 구현됨
- 우선순위 스케줄링 : 프로세스마다 우선순위를 부여하고 가장 높은 우선순위인 프로세스에게 먼저 할당
- 대기하는 시간이 길어질 수록 우선순위를 높이는 aging을 사용하여 starvation 예방
3.4.2 선점형 스케줄링
- Round Robin : time-slice를 정의하고 각 프로세스가 time-slice 만큼 할당 받고 다음 프로세스에게 넘겨줌
- 준비 queue는 circular queue로 구현됨
- 전체 작업 시간은 길어지지만 평균 응답 시간은 짧아짐
- SRF(Shortest Remaining time First) : SJF와 달리 실행 중간에 더 짧은 프로세스가 추가되면 더 짧은 프로세스로 전환됨
- 다단계 큐 : 우선순위에 따라 여러 개의 큐를 준비함
- 각 큐별로 다른 스케줄링 알고리즘 적용 가능
- 프로세스가 큐 사이 이동 불가능
- 높은 우선순위 큐가 비어있을 때 다음 우선순위 큐 실행 가능
- starvation 가능성 존재
- 다단계 피드백 큐 : 프로세스의 큐 간 이동 허용
- 보통 CPU burst time에 따라 우선순위 구분
- CPU 시간을 너무 많이 사용하면 낮은 우선순위 큐로 이동
- 오래 대기하면 높은 우선순위 큐로 이동
- e.g. 8ms RR 스케줄링, 16ms RR 스케줄링, FCFS 스케줄링 순으로 큐 설정

Leave a comment